|
| Project Info |
|
 |

|
NEW!
Neuroph 2.98 Released
Neuroph 2.98 is a maintainance release and comes with minor API improvements, cleanup of unstable features and bugfixes.
From this version Neuroph is also available on Maven Central repository.
Read the full announcement here
Register to join the Neuroph community by filling the registration form Registration is optional, and registered users will have priority in support, feature requests, and will have opportunity to participate in closed and exclusive Neuroph events and activities.
Please fill the quick survey to help us improve Neuroph for teaching neural networks
Neuroph 2.94 Released Bug fixes, improved examples, multithreaded cross validation!
Neuroph Manifesto The future of Neuroph!
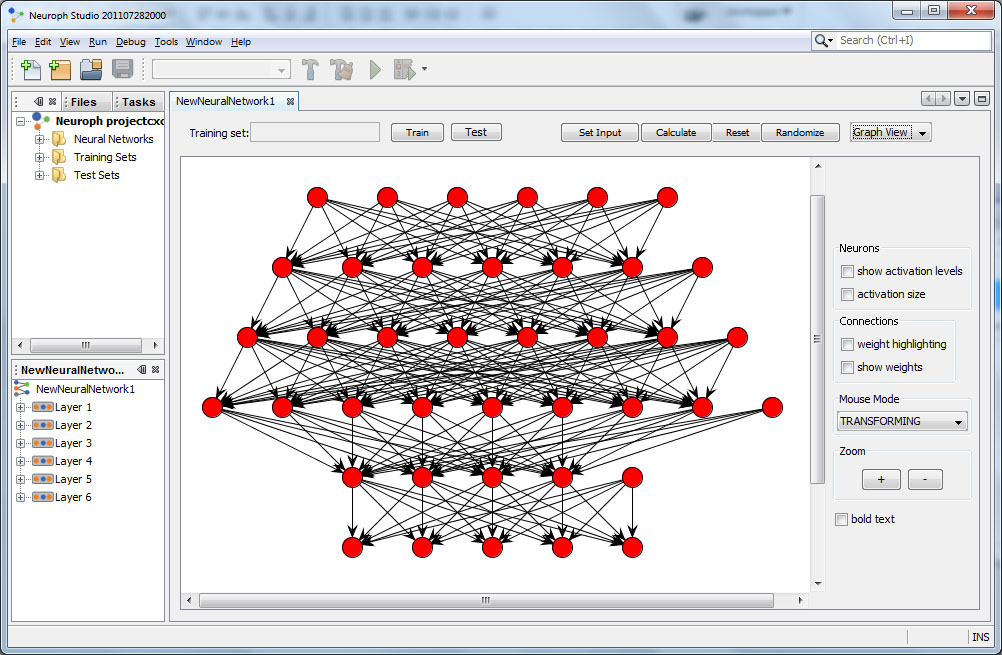
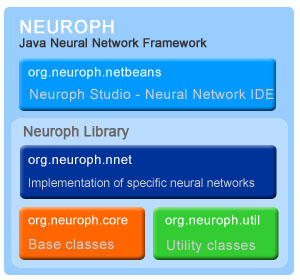
Neuroph is lightweight Java neural network framework to develop common neural network architectures. It contains well designed, open source Java library with small number of basic classes which correspond to basic NN concepts. Also has nice GUI neural network editor to quickly create Java neural network components. It has been released as open source under the Apache 2.0 license, and it's FREE for you to use it.
 |
 |
Neuroph simplifies the development of neural networks by providing Java neural network library and GUI tool that supports creating, training and saving neural networks.
If you are beginner with neural networks, and you just want to try how they work without going into complicated theory and implementation, or you need them quickly for your research project the Neuroph is good choice for you. It is small, well documented, easy to use, and very flexible neural network framework.
More details about supported networks and other features is available here
|

|
Great Neuroph review by File Croco |
 |
NEW! Nice Neuroph video review by FindMySoft |
 |
Softpedia guarantees that Neuroph is 100% Free, which means it does not contain any form of malware, including but not limited to: spyware, viruses, trojans and backdoors. |
 |
The Famous Software Award has been initiated by FamousWhy.com to recognize "Famous Software", which come up with innovative and efficient ways to reflect the best relationship with users assuring their satisfaction. Important criterias for this award:
- originality, creativity and vision;
- professional appearance and structure;
- flexibility through integration across multiple-platforms;
- leadership in the software sector.
|
 |
5 Star Award and 100% Clean by SoftSea |
|
|