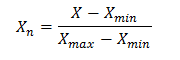|
FACE RECOGNITION USING NEURAL NETWORK An example of face recognition using characteristic points of face By Jovana Stojilkovic, Faculty of Organizational Sciences, University of Belgrade an experiment for Intelligent Systems course
Introduction System for face recognition is consisted of two parts: hardware and software. This system is used for automatic recognition users or confirmation of password. For input is used either digital pictures or video frame from same video. State institution and some private organization are using this systems for face recognition especially for identification face by video cameras like input parameter or for biometrics system for checking identity using cameras and 3D scanners. System must to recognize where is face on some picture, to take it from picture and to do verification. There are many ways for verification, but the most popular is recognition of faces characteristics. Face has about 80 characteristic parameters some of them are: width of nose, space between eyes, high of eyehole, shape of the zygotic bone and jaw width.
Face specification is made of these parameters and inserted in database as a representation of that person. Except this, there is a process of face recognition where system has a database with pictures taken from different angles. In this case, system first recognizes a position of face at picture, and with this information compares face with others from database in similar position.
Introduction to the problem The objective is to train the neural network to recognize face from picture. First thing that is needed in order to do is to have a data set. The neural network will take some picture's parameters for input and try to predict a person how has this characteristic.
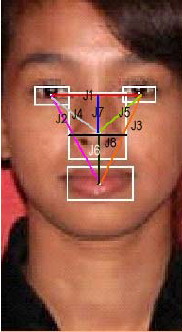
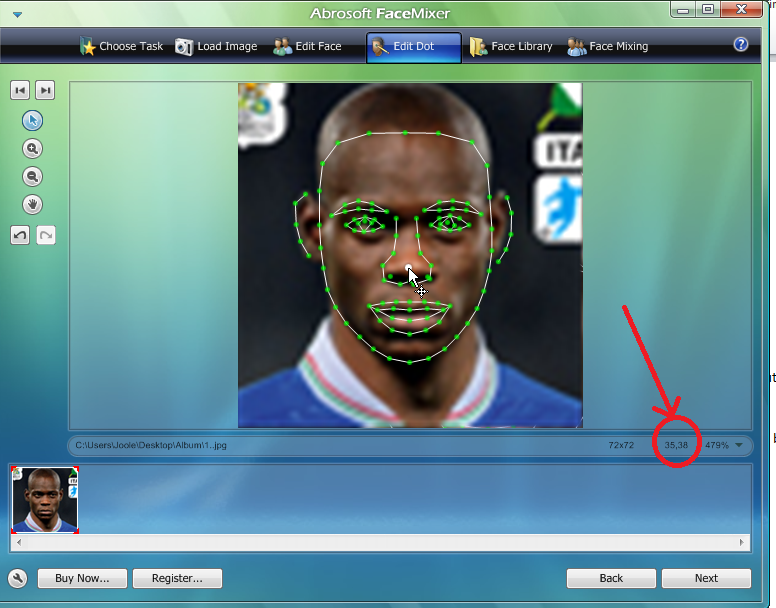
About data set Preparing data set for this experiment is the hardest part of it. Data must be good prepared: 1. First we must to find some pictures - I found some pictures of football players of Euro2012. 2. Choice characteristic parameters: I take only 8.
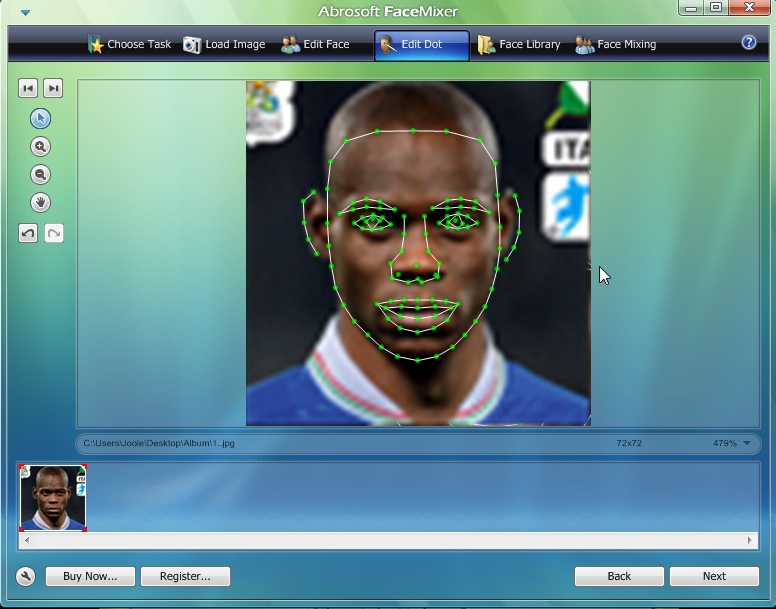
3. Find a program which can do face extraction in sense to find characteristic points. You can take Abrosoft like me. Process of face extraction:
4. Calculate parameters from point 2, using coordinates taken from picture. Distance Formula: Given the two points (x1, y1) and (x2, y2), the distance between these points is given by the formula:
5. This data must be normalized. Normalization is process of correction data values in order to be in interval 0-1 using
6. 8 normalized data is made for every image and present vector with 8 input parameters. Number of different people on the images present number of output. (In these case 15) 7. Putting data to txt file with distance of 1 tab
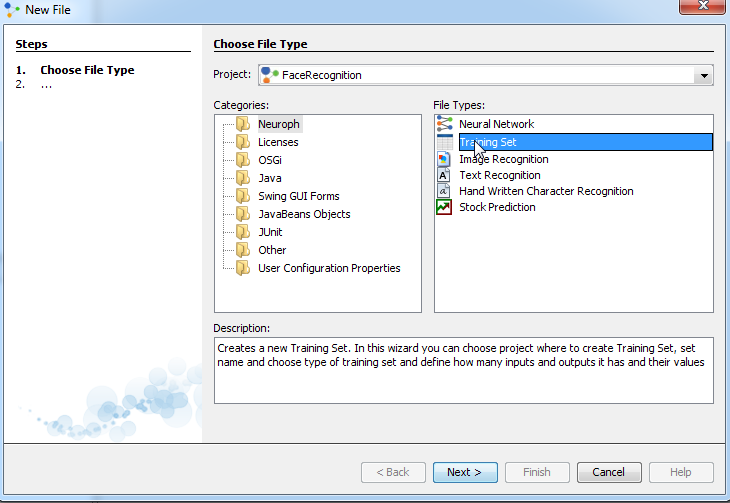
Training Neural Network for Face Recognition with Neuroph Studio In order to train a neural network, there are five steps to be made: 1. Create a Neuroph project 2. Create a training set 3. Create a neural network 4. Train the network 5. Test the network to make sure that it is trained properly
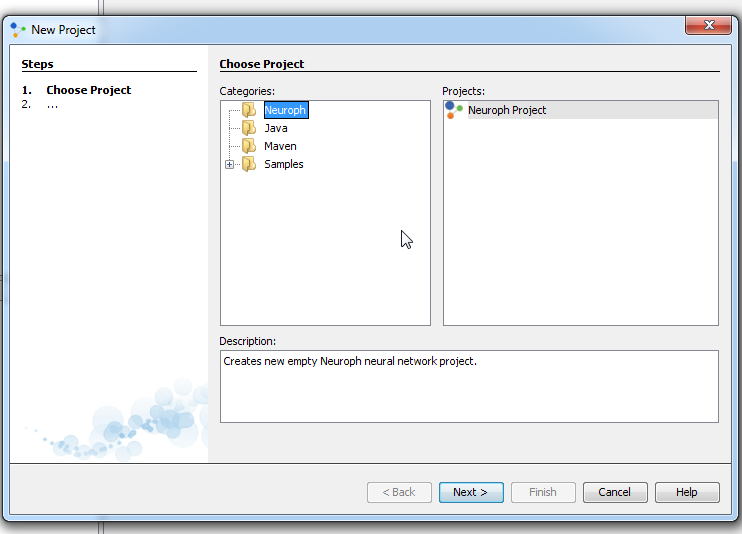
Step 1. To create Neuroph Project click File > New Project Then, select Neuroph Project and click Next.
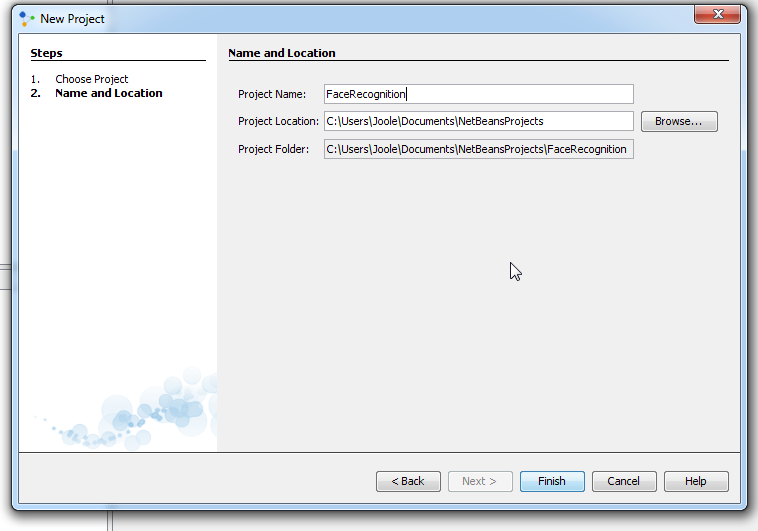
Enter project name and location, click Finish.
A new project is created and it will appear in the 'Projects' window, in the top left corner of Neuroph Studio.
Step 2. Create a training set To teach the neural network we need training data set. The training data set consists of input signals assigned with corresponding target (desired output). The neural network is then trained using one of the supervised learning algorithms, which uses the data to adjust the network's weights and thresholds so as to minimize the error in its predictions on the training set. If the network is properly trained, it has then learned to model the (unknown) function that relates the input variables to the output variables, and can subsequently be used to make predictions where the output is not known. To create a trainig set go File - > New File- >Trainig Set
Then, select Training set and click Next.
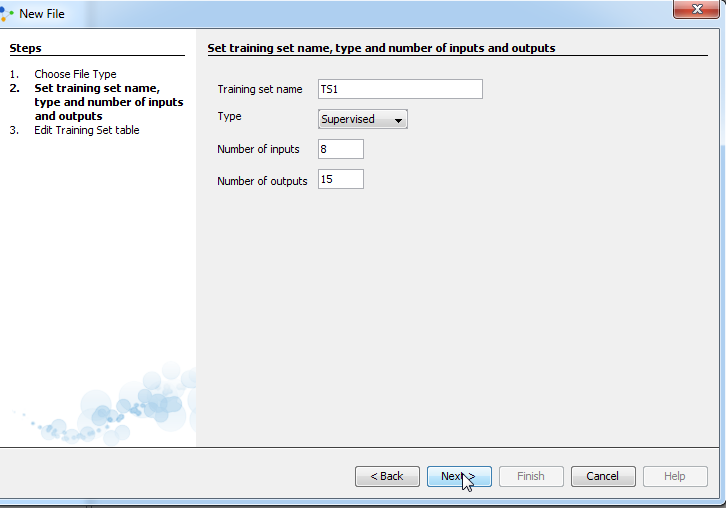
Enter training set name. Select the type of supervised. In general, if you use a neural network, you will not know the exact nature of the relationship between inputs and outputs if you knew the relationship, you would model it directly. The other key feature of neural networks is that they learn input/output relationship through training. There are two types of training used in neural networks, with different types of networks using different types of training. These are supervised and unsupervised training, of which supervised is the most common. In supervised learning, the network user assembles a set of training data. The training data contains examples of inputs together with the corresponding outputs, and the network learns to infer the relationship between the two. For an unsupervised learning rule, the training set consist of input training patterns only. Our, normalized, data set, that we create above, consists input and output values. Therefore we choose supervised learning. In field Number of inputs enter 8 and in field number of outputs enter 15 and click next:
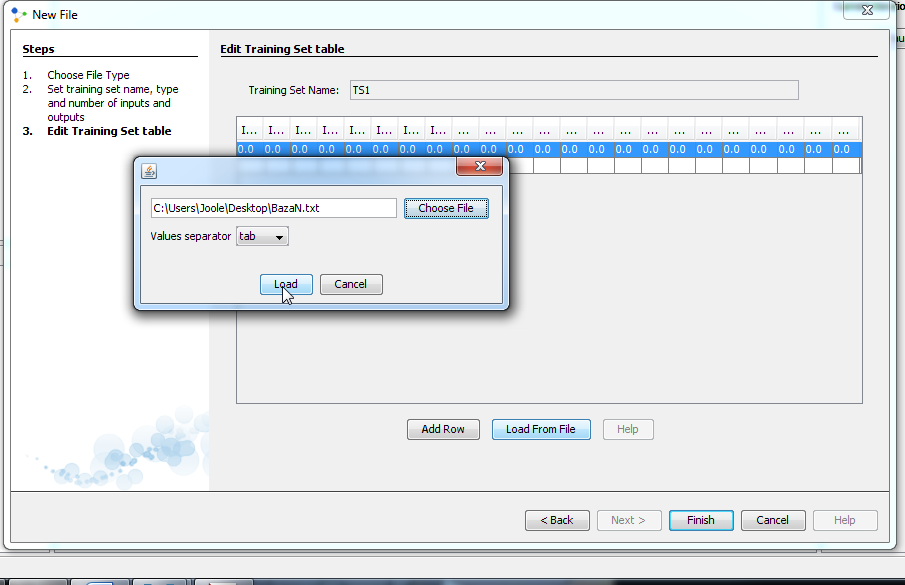
Then you can create set in two ways. You can either create training set by entering elements as input and desired output values of neurons in input and output label, or you can create training set by choosing an option load file. The first method of data entry is time consuming, and there is also a risk to make a mistake when entering data. Therefore, choose second way and click load from file.
Click on Choose File and find file named bazaN.txt. Then select tab as values separator. In our case values have been separated with tab. In some other case values of data set can be separated on the other way. When you finish this, click on Load.
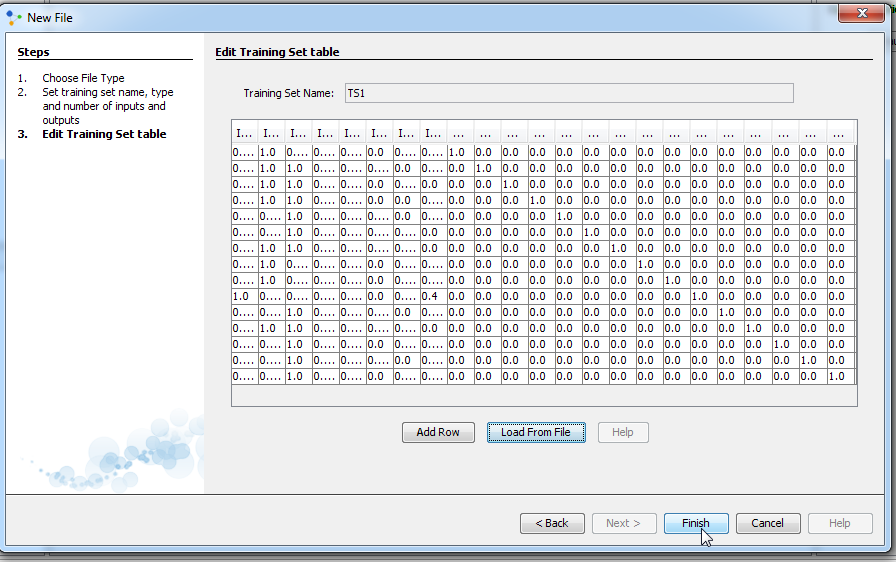
A new window will appear and table to the window is our training set. We can see that this table has a total of 23 columns which is fine because the 16 columns represents input values and other 7 columns represents output values. We can also see that all data are in the certain range, range between 0 and 1. Click Finish and new training set will appear in the Projects window. We made Training set.
Training attempt 1Step 3.1 Create a Neural Network Now we need to create neural network. In this experiment we will analyze several architecture. Each neural network which we create will be type of Multi Layer Perceptron and each will differ from one another according to parameters of Multi Layer Perceptron. Create Multi Layer Perceptron network Click File > New File Select desired project from Project drop-down menu, Neuroph as category, Neural Network file type and click next.
Enter network name, select Multi Layer Perceptron, click next.
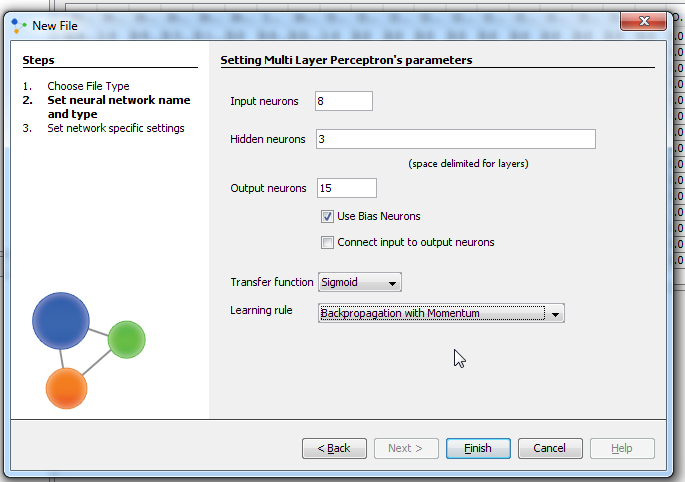
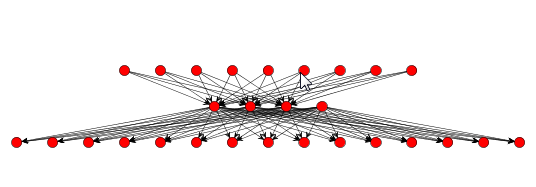
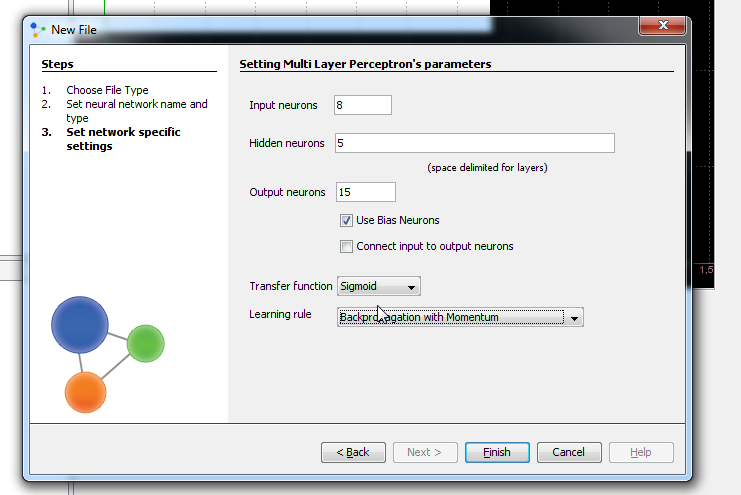
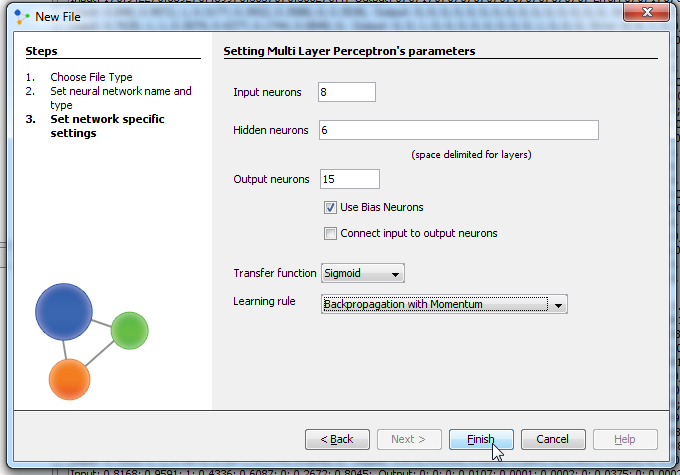
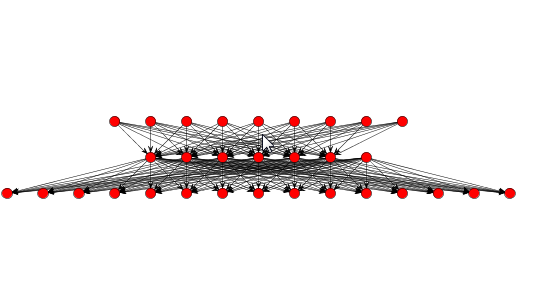
In next window we set input, hidden and output neurons. Input neurons - number of pictures parameters for experiment Output neurons - number of people who will be recognized Problems that require more than one hidden layers are rarely encountered. For many practical problems, there is no reason to use any more than one hidden layer. One layer can approximate any function that contains a continuous mapping from one finite space to another. Deciding the number of hidden neuron layers is only a small part of the problem. We must also determine how many neurons will be in each of these hidden layers. Both the number of hidden layers and the number of neurons in each of these hidden layers must be carefully considered. There are 2 problems if we take many neurons in hidden layers: Underfitting occurs when there are too few neurons in the hidden layers to adequately detect the signals in a complicated data set. Overfitting occurs when the neural network has so much information processing capacity that the limited amount of information contained in the training set is not enough to train all of the neurons in the hidden layers. A second problem can occur even when the training data is sufficient. An inordinately large number of neurons in the hidden layers can increase the time it takes to train the network. The amount of training time can increase to the point that it is impossible to adequately train the neural network. We've decided to have 3 layer and 8 neuron in this first training attempt. Than we check 'Use Bias Neurons' option and choose 'Sigmond' for transfer function (because our data set is normalized). For learning rule we choose 'Backpropagation with Momentum'. The momentum is added to speed up the process of learning and to improve the efficiency of the algorithm. Bias neuron is very important, and the error-back propagation neural network without Bias neuron for hidden layer does not learn. The Bias weights control shapes, orientation and steepness of all types of Sigmoidal functions through data mapping space. A bias input always has the value of 1. Without a bias, if all inputs are 0, the only output ever possible will be a zero. At the right side, we can see Combo box with different views. Choose Graph View, and you can see network.
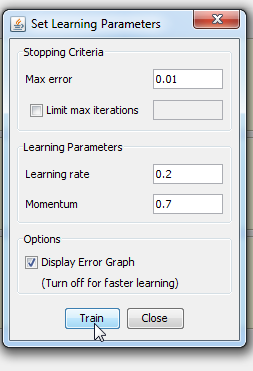
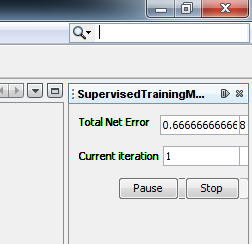
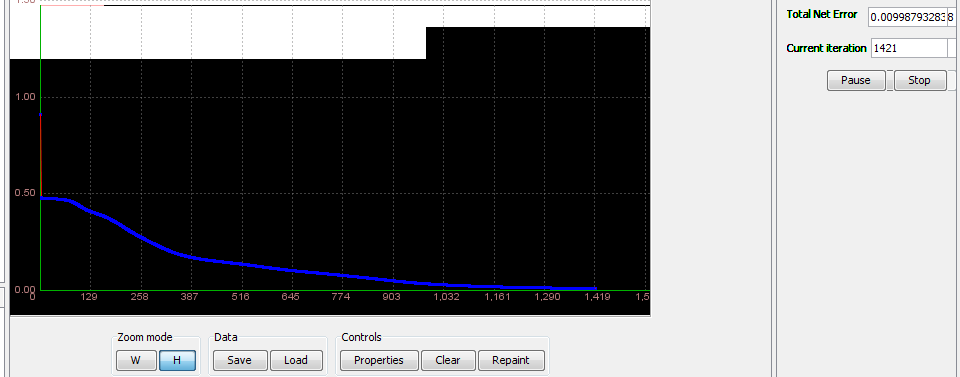
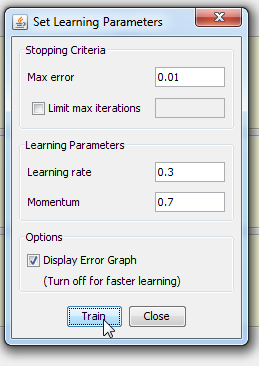
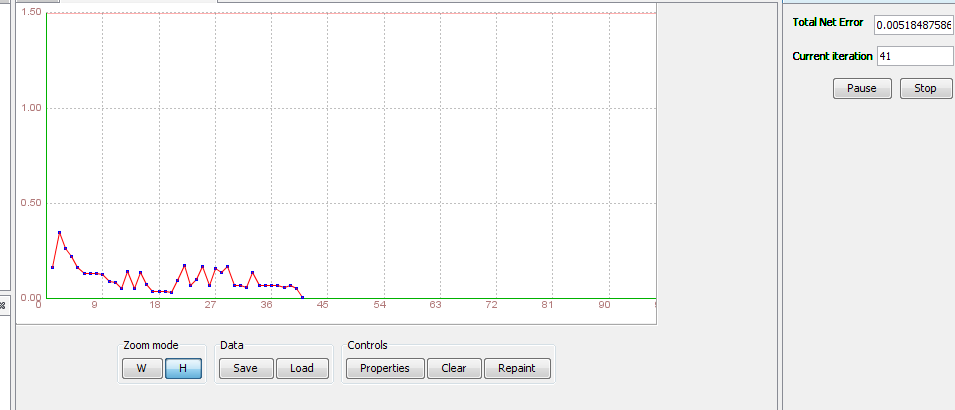
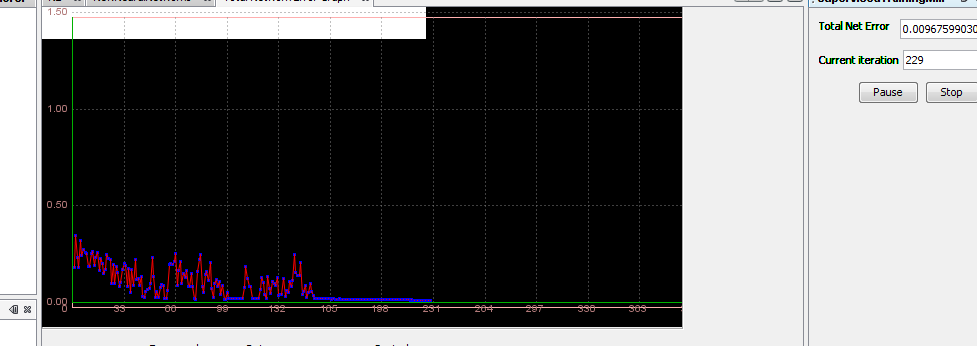
Step 4.1 Train the network Standard training techniques Standard approaches to validation of neural networks are mostly based on empirical evaluation through simulation and/or experimental testing. There are several methods for supervised training of neural networks. The backpropagation algorithm is the most commonly used training method for artificial neural networks. Backpropagation is a supervised learning method. It requires a data set of the desired output for many inputs, making up the training set. It is most useful for feed-forward networks. Main idea is to distribute the error function across the hidden layers, corresponding to their effect on the output Now that we have created a neural network it is time to do some training. To start network training procedure, in network window select training set, named TS1,and click Train button. In Set Learning parameters dialog use default learning parameters. When the Total Net Error value drops below max error, which is by default 0.01, the training is complete. If the error would be smaller we would get a better approximation. Next thing we should do is determine the values of learning parameters, learning rate and momentum. Learning rate is one of the parameters which governs how fast a neural network learns and how effective the training is. Let us assume that the weight of some synapse in the partially trained network is 0.2. When the network is introduced with a new training sample, the training algorithm demands the synapse to change its weight to 0.7 (say) so that it can learn the new sample appropriately. If we update the weight straightaway, the neural network will definitely learn the new sample, but it tends to forget all the samples it had learnt previously. This is because the current weight (0.2) is a result of all the learning that it has undergone so far. So we do not directly change the weight to 0.7. Instead, we increase it by a fraction (say 25%) of the required change. So, the weight of the synapse gets changed to 0.3 and we move on to the next training sample. This factor (0.25 in this case) is called Learning Rate. Proceeding this way, all the training samples are trained in some random order. Learning rate is a value ranging from zero to unity. Choosing a value very close to zero, requires a large number of training cycles. This makes the training process extremely slow. On the other hand, if the learning rate is very large, the weights diverge and the objective error function heavily oscillates and the network reaches a state where no useful training takes place. The momentum parameter is used to prevent the system from converging to a local minimum or saddle point. A high momentum parameter can also help to increase the speed of convergence of the system. However, setting the momentum parameter too high can create a risk of overshooting the minimum, which can cause the system to become unstable. A momentum coefficient that is too low cannot reliably avoid local minima, and can also slow down the training of the system.
Now, click Train button and see what happens. Because number of iteration passed 50000, I stop it and create new Training Training attempt 2
Network wasn't successfully trained, therefore is not possible to do testing. We make the new one.
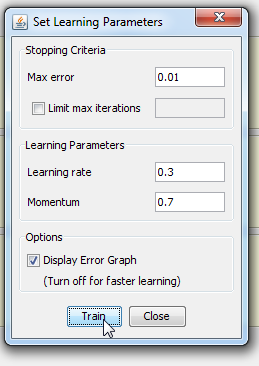
>We made a new network called it N2, and now we have 5 hidden neurons Step 3.2 Create a neural network - File-> New File -> Neural network
Again we take usual training
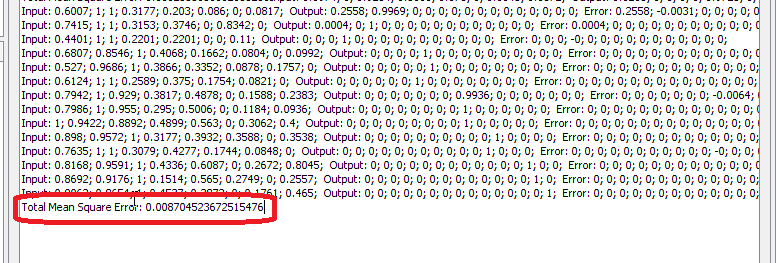
We got good results: network is trained. Now we can test it. 5.3 Test the network
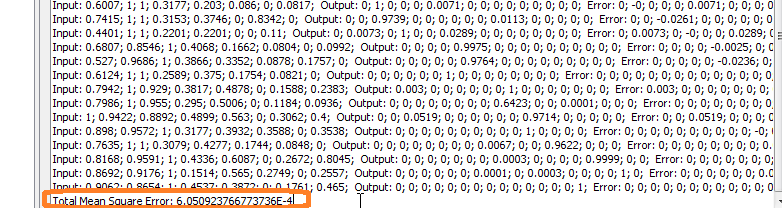
For the first time, we will random choose 3 observations which will be subjected to individual testing. Those observations and their testing results are in the following table:
Training attempt 4
In these case, total square error is bigger than one from Training 3 5.4 Test the network
Again, we will random choose 3 observations which will be subjected to individual testing (the same used in attempt 2). Those observations and their testing results are in the following table:
Training attempt 5>We made a new network called it N3, and now we have 6 hidden neurons Step 3.3 Create a neural network - File-> New File -> Neural network
Again, first we take usual training
In these case, total square error is very small 5.5 Test the network
But, total square error is too big
So if we check our test person we will see:
At the end Save neural network To save the neural network as Java component click [Main menu > File > Save] and use the .nnet extension. The network will be saved as serialized Multilayer Perceptron object. ConslusionDuring this experiment, we created 3 different architectures and one basic training set . We normalize the original data set using a linear scaling method. Through 5 basic steps we explained in detail the creation, training and testing neural networks. If the network architecture using a small number of hidden neurons training will become excessively and the network may over fit no matter what are the values of training parameters. Through the various tests we have demonstrated the sensitivity of neural networks to high and low values of learning parameters. We have shown that the best solution to the problem of face recognition. The hardest part was preparation of data. So after all, I may say that Neuroph is good for this purpose, but algorithm is not easy. My data set is small and taking only one picture of each face. Better result we will get if we have pictures from many positions of face and face expressions. In the table below can been seen the overall results of this experiment. Best solution is indicated in pink color.
DOWNLOAD See also:
|